Haciendo accesible la información a las máquinas: web de identidades y servicios (Parte II)
En la primera parte de este artículo hablé del problema del crecimiento exponencial de la información disponible en internet y cómo la web de datos es una red de bloques semánticamente relacionados de información, de tal forma que sean interpretables y aplicables por una máquina que nos facilite el trabajo.

En este contexto, una conexión es el resultado de bloques de información que apuntan a más información contenida en otro bloque, a través de una URI, de la misma manera que los sitios web se enlazan entre sí. De esta manera, las máquinas pueden recorrer los bloques de información para leerla e interpretarla.
La web de identidades
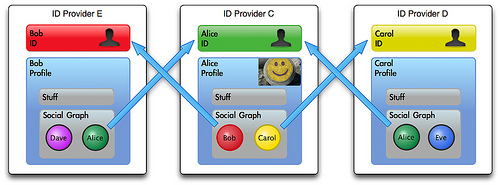
También los proveedores de identidades muy probablemente vayan a referirse a sus usuarios a través de URIs en el futuro. Una conexión social consistirá en la URI de un usuario que apunte a la URI de otro usuario o a un proveedor de identidades. Dependiendo del permiso que el usuario le otorgue, una máquina podría de la misma manera que con la web de datos, arrastrarse por los vínculos entre las identidades de un usuario y el siguiente.
¿Con qué propósito? La web de identidades es una super gráfica social que abarca múltiples proveedores de identidad. Si, como mencionábamos en el artículo anterior, en aras de buscar la privacidad o el incremento de la cuota de usuarios para el servicio que ofrezco, nos topamos con muros entre los distintos proveedores de servicios, una infraestructura así nos sería muy útil para cualquiera de las funciones sociales que requerimos. Por ejemplo:
- Puedes estar interesado en cuál es el mejor libro que han leído tus amigos de tu salón de clases y la búsqueda te regresaría información sobre los libros que han comprado o actualizaciones de estados (tweets también) que tengan relación con libros y que tus amigos hayan hecho accesibles dependiendo del nivel de privacidad que elijan.
- ¿Quieres saber cuándo alguno de tus amigos estará por Buenos Aires? Este tipo de búsqueda involucraría la geolocalización de tus amigos y estaría relacionado con el proceso de interpretación que llevaría a cabo una máquina sobre el significado y la localización de esta ciudad.
- ¿Quieres sincronizar tu libreta de contactos? Una tarea que puede ser llevada a cabo permanentemente actualizaría los cambios de direcciones y números telefónicos de tus amigos automáticamente.
La web de servicios
Luego de echarle un vistazo a las primeras dos tendencias, nos enfocaremos en la web de servicios, que es la que hace que determinados servicios sean accesibles y procesables para las máquinas. Los tres enfoques que hemos observado tienen en común una estructura básica que se rige por principios como la simplicidad, la descentralización y otros.
El sector de los servicios es el más grande del mundo y hay presión por todos lados para hacer esos servicios más fáciles y más ampliamente accesibles. La adaptabilidad al cambio también se tiene en alta estima.
El esfuerzo por estandarizar la arquitectura orientada a servicios (SOA) y los servicios webs es algo que tiene años de estar en proceso y aún no tenemos una definición clara de lo que constituye un servicio a nivel conceptual. La interfaz, que es el formato de lo que entra y sale del servicio es usualmente descrita de forma formal, pero no lo que el servicio hace, semánticamente hablando.
Algunos esfuerzos en este respecto son OWL-S, WSMO y WDSL-S, pero ninguno ha salido de sus confines académicos.
Hoy en día hay todo tipo de servicios con distintos niveles de complejidad y se espera que la cantidad crezca exponencialmente. Los servicios siguen diferentes estándares y muchos de ellos son unidireccionales y están diseñados para que los humanos los consuman. El problema con todo esto es que hay miles de servicios que están disponibles, pero que difícilmente son encontrables sin una descripción comprensible por una máquina.
¿De qué serían capaces las máquinas si los servicios estuvieran anotados con estas descripciones semánticas?
Alexander Korth nos habla básicamente de:
- Descubrimiento de servicios con más facilidad: Debido a que existe un índice de servicios web, una máquina cuya tarea sea encontrar el servicio apropiado para un problema particular puede escoger entre los que formen parte de ese índice.
- Contratación y ejecución: Una vez eligió un servicio, la máquina podría revisar los términos del mismo y decidir sobre detalles de ejecución. ¿Cuál es la opción más económica? ¿Cada cuánto necesitaremos usar el servicio?
- Manejo de cuentas: Dependiendo del grado de autonomía de la máquina, podrían automatizarse los procesos de cobro o de repartición de ganancias.
- En base a la experiencia, la máquina podría reemplazar un servicio fallido con uno equivalente, además de evaluar el servicio y publicar un review.
- Orquestación de servicios: Una máquina podría, eventualmente, dividir una tarea en sub-tareas; y descubrir, contratar y orquestrar servicios para resolver esas sub-tareas. De esa forma se podría acelerar el proceso, evitar redundancias y evitar el encadenamiento de servicios, donde el resultado de uno sería el punto de partida del siguiente.
Algunos proyectos están trabajando con estas ideas, tales como SUPER, SHAPE y TripCom. Los futuros escenarios, dice Korth, están limitados únicamente por nuestra imaginación. Podemos hablar de máquinas que realizan tareas autónomamente en beneficio de su dueño o de una compañía, dependiendo del grado de libertad que se le otorgue para operar.
¿Qué les parece a ustedes? Suena un poco a ciencia ficción, ¿no? Después de todo la idea de que el ser humano cada vez hará menos tareas de estas que suelen consumir tiempo (y por lo tanto, dinero), no era tan descabellada.